Резервирование Asterisk при помощи Heartbeat и Rsync
Одним из наиболее простых способов зарезервировать Asterisk является использование heartbeat для резервирования сети и rsync для синхронизации файлов конфигурации по сети. Основным минусом использования rsync является отсутствие синхронизации в реальном времени. Если такая синхронизация нужна, то можно использовать общую файловую систему на обоих серверах при помощи общего NAS, если необходимо синхронизировать большой объем данных или использовать drbd для небольшого объема данных.
Опыт коллег подсказывает что drbd для Asterisk является не очень хорошим решением, особенно при интенсивном обмене данными с жестким диском. Rsync как и drbd является бюджетными решениями, я бы не рекомендовал их использовать если есть возможность поставить NAS или Blade серер. Но так как сам Asterisk является зачастую бюджетным решением, вероятно будет использовано подобное решение. Еще одним существенным минусом является невозможности географически распределить систему. Например, что бы серверы находились в разных дата центрах и соответственно в разных сетях. Теоретически, даже с heartbeat это можно сделать, но потребуется сложная конфигурация. Лучшим решением, в данном случае, будет использование системы предназначенной для работы в такой конфигурации. Итак, идея резервирования заключается в следующем: Есть основной сервер Asterisk, который обрабатывает вызовы, есть резервный сервер, на который через некоторый период времени синхронизируется конфигурация, записи разговоров и CDR записи о вызовах. Синхронизация происходит при помощи скриптов rsync в cron. На сервере запущен heartbeat с общим IP который, в случае отказа сети или сервера(причем отказа наподобие зависания или полного отказа сети), переключает общий shared IP на резервный сервер, стартует Asterisk и связанные с ним сервисы, затем позывает администратору письмо об аварии и отключает автоматическую синхронизацию по cron. Соответственно, после аварии, требуется ручное переключение и синхронизация файлов с резервного на основной сервер(записей разговоров и cdr как минимум).Этот тоже можно отнести к минусам решения. Для слежения за доступностью процессов, например Asterisk, я рекомендую использовать Monit. Обращаю внимание что heartbeat не следит за доступностью процессов.
Итак, процесс развертывания такого решения можно разделить на несколько этапов:
1) Установка необходимого софта на основной и резервный сервер
2) Настройка резервирования на свитчах
3) Настройка резервирования сетевых интерфейсов bonding
4) Настройка heartbeat
5) Настройка rsync для asterisk и остальных необходимых сервисов
Установка необходимого софта на основной и резервный сервер
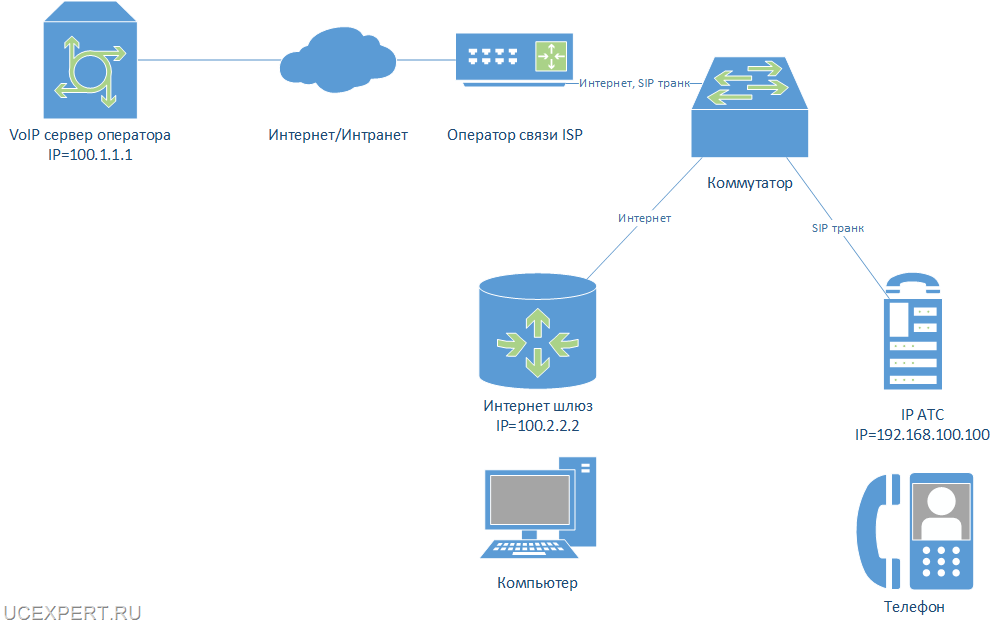
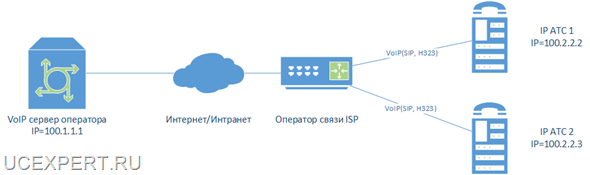
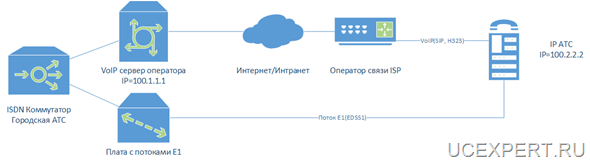
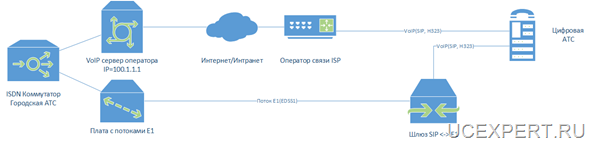
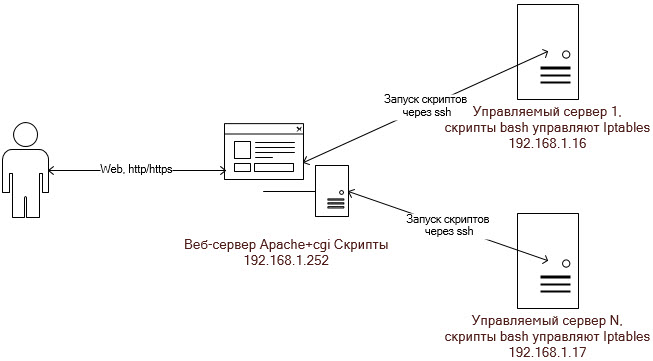
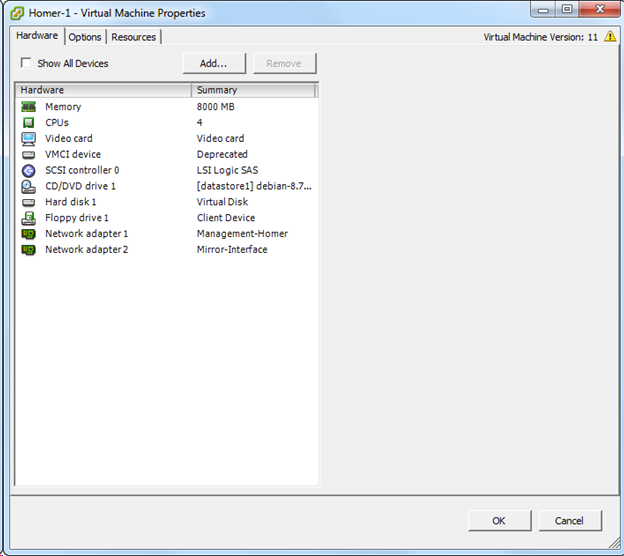
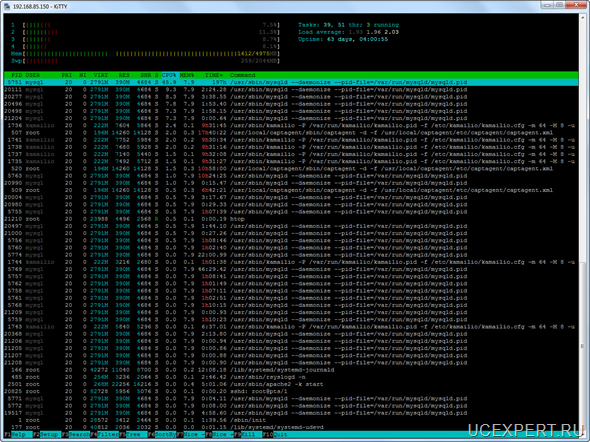
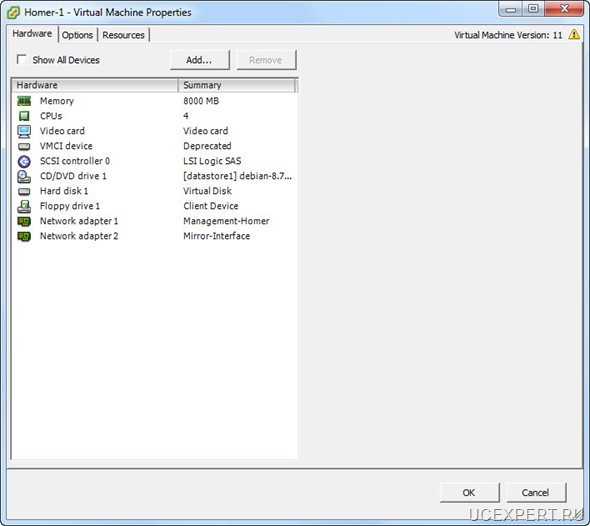
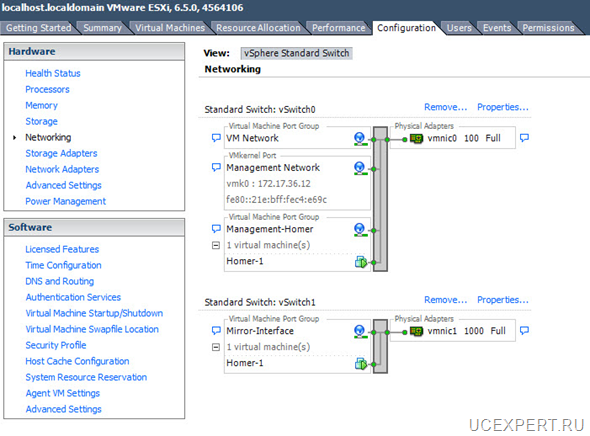
В примере необходимо зарезервировать Asterisk, конфигурация которого хранится на диске /etc/asterisk, записи разговоров абонентов и CDR вызовов, информация о которых хранится в БД MySQL, файлы с веб сервера Apache, файлы webmin.

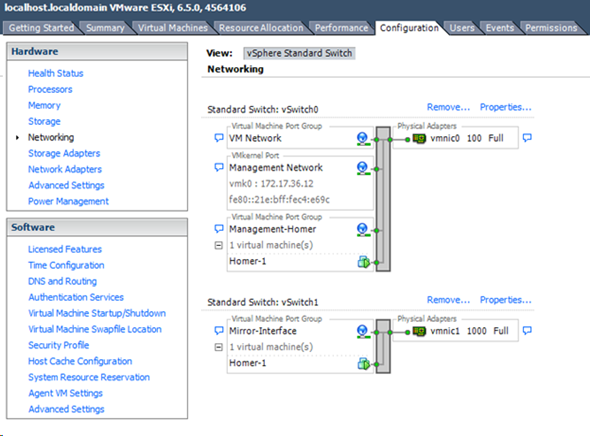
Если представить графически, получается такая схема:

В качестве софта я использовал дистрибутив Thirdlane. Более подробно читайте в
Реализация мульти доменов (multi tenant) на базе Asterisk — Thirdlane
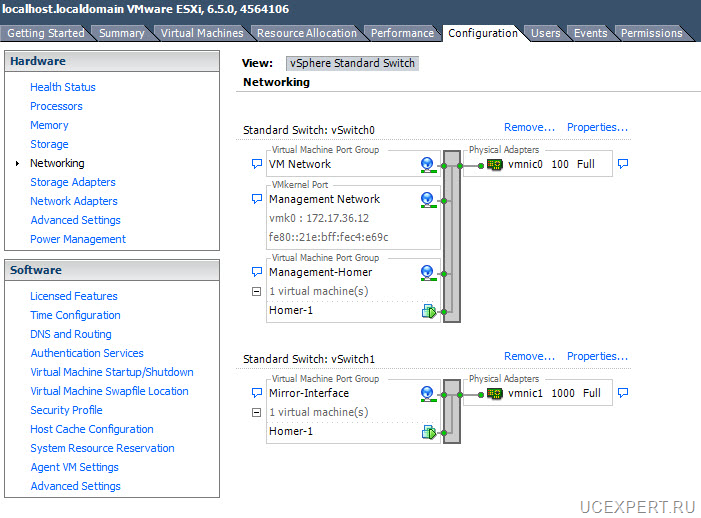
Настройка резервирования на свитчах
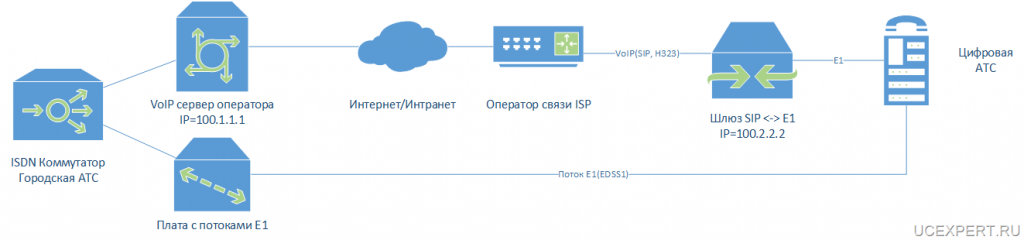
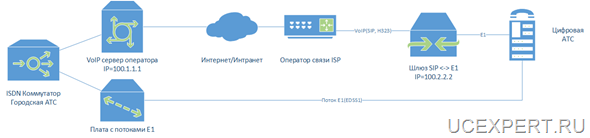
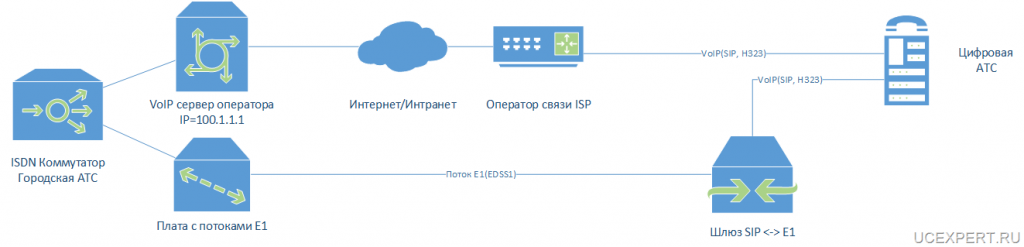
Если вы резервируете коммутаторы через которые подключаются серверы, то на серверах необходимо создать бондинг(bonding), те объединить два сетевых интерфейса в один логический и указать какой из них является основным,а какой должен быть использован при отказе основного. На основном и резервном серверах должно быть по два сетевых интерфейса. Соответственно первый сетевой интерфейс eth1 подключается к основному коммутатору, а второй eth1 подключается к резервному коммутатору. В примере, в одном бонде находятся два интерфейса в разных VLAN, первый VLAN для внешних интернет подключений, а второй для сети управления management.
В виде схемы это выглядит так:

Настройка bonding на сервере NODE1 на примере Debian:
debian:~# cat /etc/network/interfaces # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). # The loopback network interface auto lo iface lo inet loopback auto bond0 iface bond0 inet manual slaves eth0 eth1 bond_mode active-backup bond_miimon 100 bond_downdelay 200 bond_updelay 200 auto bond0.4 iface bond0.4 inet static address 84.52.103.46 netmask 255.255.255.224 gateway 84.52.103.51 vlan_raw_device bond0 auto bond0.999 iface bond0.999 inet static address 10.17.36.14 netmask 255.255.255.192 post-up /sbin/ip r a 10.0.0.0/16 via 172.17.36.62 post-up /sbin/ip r a 10.17.0.0/16 via 10.17.36.62 post-up /sbin/ip r a 10.168.133.0/24 via 10.17.36.62 vlan_raw_device bond0
Такие же настройки только с другими адресами будут на NODE2Далее необходимо, настроить Heartbeat:
Устанавливаем пакет,
Авторизация, на обоих узлах файлы одинаковые:Листинг /etc/ha.d/authkeys
auth 1
1 crc
Определяем ресурсы которыми должны управляться heartbeat:Листинг, на обоих узлах файлы одинаковые /etc/ha.d/haresources
tlane-n1 IPaddr::84.52.103.40/255.255.255.224/eth0 MailTo::user@ucexpert.ru::AsteriskCluster_take_over postfix pbxportal httpd xinetd webmin #mysqld
Листинг файла /etc/ha.d/ha.cf
На узле NODE1:
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0 # This is deprecated
keepalive 1 # Interval between heartbeat (HB«») packets.
deadtime 20 # How quickly HB determines a dead node.
warntime 10 # Time HB will issue a late HB.
initdead 40 # Time delay needed by HB to report a dead node.
udpport 694 # UDP port HB uses to communicate between nodes.
#ping 192.168.160.103 # Ping virtual host to simulate network resource.
ping 195.52.103.35 # проверка доступности default gw
#bcast eth1 # Which interface to use for HB packets.
ucast eth1 10.17.36.15
#auto_failback on # Auto promotion of primary node upon return to cluster.
auto_failback off
node tlane-n1
node tlane-n2
respawn hacluster /usr/lib/heartbeat/ipfail
На узле NODE2:
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0 # This is deprecated
keepalive 1 # Interval between heartbeat (HB«») packets.
deadtime 20 # How quickly HB determines a dead node.
warntime 10 # Time HB will issue a late HB.
initdead 40 # Time delay needed by HB to report a dead node.
udpport 694 # UDP port HB uses to communicate between nodes.
#ping 192.168.160.103 # Ping virtual host to simulate network resource.
ping 84.52.103.35 # проверка доступности default gw
#bcast eth1 # Which interface to use for HB packets.
ucast eth1 10.17.36.14
#auto_failback on # Auto promotion of primary node upon return to cluster.
auto_failback off
node tlane-n1
node tlane-n2
respawn hacluster /usr/lib/heartbeat/ipfail
Вручную добавлен скрипт который уведомляет по почте о том что heartbeat переключился на резервный сервер
и посылает письма, так же отключает синхронизацию с мастер сервера.
[root@tlane-n2 ha.d]# cat /etc/ha.d/resource.d/custom-actions
mv /sync-dir.sh /sync-dir.sh_cluster_FAIL!!! # Отключаем автоматическую синхронизацию по cron
echo -e "Subject: Thirdlane MASTER NODE DOWN n" | sendmail -fuser@ucexpert.ru user@ucexpert.ru # отправляем уведомление о падении основного сервера
Обращаю внимание что после настройки heartbeat нужно что бы Asterisk слушал только на shared IP:
/etc/asterisk/sip.conf: [general]
bindport=9966 # необходимо если вы используете нестандартный порт
;bindaddr=0.0.0.0
bindaddr=195.52.103.40
Выключен автозапуск сервисов которыми должен управлять heartbeat(пример CentOS):
chkconfig postfix off chkconfig pbxportal off
chkconfig httpd off chkconfig xinetd off chkconfig webmin off
Скрипты для управления кластером heartbeat находятся в /usr/share/heartbeat
Для запуска heartbeat(в centOS):
service heartbeat start
Настройка Rsync
Синхронизация конфигурации при помощи утилиты rsync.
На первом сервере NODE 1 необходимо настроить
1) Сервер rsync с помощью которого клиент rsync на втором узле будет забирать файлы из необходимых директорий. Требуется изменить два файла:
/etc/xinetd.d/rsync
service rsync
{
disable = no
socket_type = stream
wait = no
user = root
only_from = 10.36.14 10.17.36.15 localhost
server = /usr/bin/rsync
server_args = —daemon
log_on_failure += USERID
}
Второй файл:
[root@tlane-n1 /]# cat /etc/rsyncd.conf
log file = /var/log/rsyncd.log
transfer logging = true
#название шары:
[asterisk]
#путь к директори на сервере которую будем бекапить:
path = /etc/asterisk/
#пользователь из под которого будем бекапить:
uid = root
#включаем режим только чтение:
read only = yes
#разрешить просмотр файлов:
list = yes
comment = Asterisk Directory !!!
#список IP-адресов, с которых разрешен доступ к шаре (через пробел):
hosts allow = 10.17.36.15, 127.0.0.1
#список пользователей rsyncd, которым разрешен доступ к шаре (через пробел)
#auth users = tlanen2
#путь к файлу с именами пользователей и паролями:
#secrets file = /etc/rsyncd.scrt
[libasterisk]
path = /var/lib/asterisk
uid = root
read only = yes
list = yes
comment = ASTDB это архиважно синхронизировать эту директорию — не менее чем /etc/asterisk
hosts allow = 10.17.36.15, 127.0.0.1
#auth users = tlanen2
#secrets file = /etc/rsyncd.scrt
[monitor]
path = /var/spool/asterisk/monitor
uid = root
read only = yes
list = yes
comment = Audiofiles directory
hosts allow = 10.17.36.15, 127.0.0.1
#auth users = tlanen2
#secrets file = /etc/rsyncd.scrt
[mysqldumps]
path = /home/mysqldumps
uid = root
read only = yes
list = yes
comment = Mysql DB directory
hosts allow = 10.17.36.15, 127.0.0.1
#auth users = tlanen2
#secrets file = /etc/rsyncd.scrt
[webmin]
#путь к папке на сервере которую будем бекапить:
path = /etc/webmin/
#пользователь из под которого будем бекапить:
uid = root
#включаем режим только чтение:
read only = yes
#разрешить просмотр файлов:
list = yes
comment = Asterisk Directory !!!
#список IP-адресов, с которых разрешен доступ к шаре (через пробел):
hosts allow = 10.17.36.15, 127.0.0.1
#список пользователей rsyncd, которым разрешен доступ к шаре (через пробел)
#auth users = tlanen2
#путь к файлу с именами пользователей и паролями:
#secrets file = /etc/rsyncd.scrt
Что бы применить настройки (в CentOS): service xinetd restart
3) Скрипты которые будут по расписанию с помощью cron делать дамп нужной нам базы данных.
crontab содержимое cron:
30 3 * * * sh /mysqldump.sh # Делаем копию базы данных и iptables каждый раз в 3 часа ночи 30 минут
Листинг скрипта mysqldump.sh
[root@tlane-n1 /]# cat mysqldump.sh
mysqldump -u root -ppassw0rd astcdrdb > /home/mysqldumps/node1-db.sql
cp /etc/sysconfig/iptables /home/mysqldumps/ # обращаю внимание что iptables копируются вместе с дампом БД
На втором сервере NODE 2
Мастер сервер NODE1 с которого забираются файлы конфигурации 10.17.36.14, а на слейве NODE2 10.17.36.15 запускается скрипт который синхронизируется с мастером каждую ночь в 4 часа по крону:
0 4 * * * sh /sync-dir.sh # Синхронизируем с мастера
Листинг скрипта sync-dir.sh
#!bin/sh
#-n — Эмуляция процесса синхронизации
#ARM=’-n’ #Эмуляция процесса синхронизации
ARM=» #Обычный режим
rsync $ARM -v —recursive —owner —delete —group —update —perms —times —copy-links 10.17.36.14::asterisk /etc/asterisk #> /dev/null 2>&1
rsync $ARM -v —recursive —owner —delete —group —update —perms —times —copy-links 10.17.36.14::libasterisk /var/lib/asterisk #> /dev/null 2>&1
rsync $ARM -v —recursive —owner —delete —group —update —perms —times —copy-links 10.17.36.14::webmin /etc/webmin #> /dev/null 2>&1
rsync $ARM -v —recursive —owner —delete —group —update —perms —times —copy-links 10.17.36.14::monitor /var/spool/asterisk/monitor #> /dev/null 2>&
rsync $ARM -v —recursive —owner —delete —group —update —perms —times —copy-links 10.17.36.14::mysqldumps /home/mysqldumps #> /dev/null 2>&1
sleep 2
#mysql -u root -ppassw0rd astcdrdb < /home/mysqldumps/node1-db.sql
sleep 2
#cp /home/mysqldumps/iptables /etc/sysconfig/iptables
sleep 2
#service iptables restart
На этом настройка закончена. Скрипт sync-dir.sh запускается по cron каждую ночь и забирает конфигурацию с основного сервера. На основном сервере NODE1 каждый день готовится дамп БД MySQL и конфигурации iptables, которые затем забираются rsync.
В случае отказа основного сервера, heartbeat переключает общий IP на резервный сервер, запускает необходимые сервисы с синхронизированной ранее конфигурацией по rsync с основного сервера.
Похожие материалы:

")

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}